BillBuddy
Health insurance assistant using RAG and advanced language models to demystify complex policies and improve healthcare literacy.
Next.jsReactTypeScriptOpenAIPineconePostgreSQLAWS S3LangchainClerk
View Project →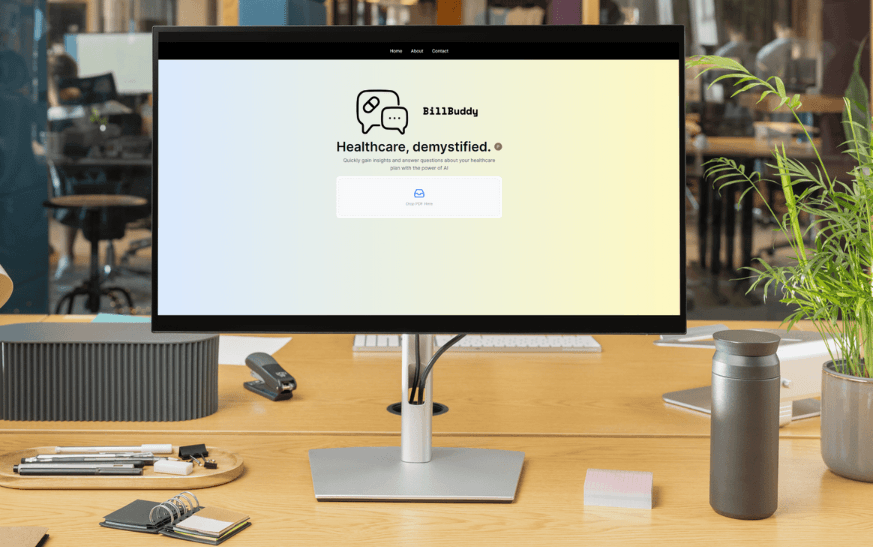
Project Overview
BillBuddy is an AI-powered platform that addresses the critical challenge of health insurance literacy by transforming complex policy documents into clear, actionable insights. The system uses advanced RAG pipelines and prompt engineering to help users understand their healthcare coverage and make informed decisions.
Key Features
- Document Analysis: Intelligent processing of insurance policies
- Natural Language Q&A: Context-aware responses to policy questions
- Vector Search: Efficient document retrieval using embeddings
- Secure Storage: Encrypted document handling with AWS S3
Technical Implementation
RAG Pipeline Architecture
I built a RAG system using Pinecone and OpenAI:
async function getContext(query: string, fileKey: string) {
// Generate embeddings for the query
const queryEmbeddings = await getEmbeddings(query);
// Retrieve top matches from Pinecone
const matches = await getMatchesFromEmbeddings(queryEmbeddings, fileKey);
// Filter matches based on relevance score
const qualifyingDocs = matches.filter(
(match) => match.score && match.score > 0.2
);
// Extract and format relevant context
let docs = qualifyingDocs.map(
(match) => (match.metadata as Metadata).text
);
return docs.join("\n").substring(0, 3000);
}
Document Processing Pipeline
I implemented a robust document processing system:
async function loadS3IntoPinecone(fileKey: string) {
// Download and process PDF
const file_name = await downloadFromS3(fileKey);
const loader = new PDFLoader(file_name);
const pages = await loader.load();
// Split documents into manageable chunks
const documents = await Promise.all(
pages.map(prepareDocument)
);
// Generate and store embeddings
const vectors = await Promise.all(
documents.flat().map(embedDocument)
);
// Upload to Pinecone with namespace
const pineconeIndex = await client.index("billbuddy");
const namespace = pineconeIndex.namespace(
convertToAscii(fileKey)
);
await namespace.upsert(vectors);
}
Prompt Engineering
I developed context-aware prompt templates for accurate responses:
const basePrompt = {
role: "system",
content: `You are an AI assistant specializing in insurance and policy matters.
Your traits include:
1. Professionalism: Maintain courteous and formal tone
2. Expertise: Deep understanding of insurance terms
3. Clarity: Explain complex concepts simply
4. Helpfulness: Provide accurate, actionable advice
5. Compliance awareness: Knowledge of regulations
CONTEXT BLOCK:
${context}
Guidelines:
1. Consider context and user concerns
2. Avoid assumptions
3. Emphasize accuracy over comprehensiveness
4. Suggest cost reduction strategies
5. Include alternative program information`
};
Technical Architecture
The application follows a modern microservices architecture:
-
Frontend Layer
- Next.js for server-side rendering
- React components for UI
- Tailwind CSS for styling
- Clerk for authentication
-
Backend Services
- Node.js API endpoints
- PostgreSQL for user data
- Pinecone for vector storage
- AWS S3 for document storage
-
AI Processing Pipeline
- OpenAI for embeddings
- Langchain for RAG orchestration
- Prompt engineering system
- Context management
Infrastructure
# Production Infrastructure
services:
frontend:
build: ./frontend
environment:
- NODE_ENV=production
ports:
- "3000:3000"
depends_on:
- api
api:
build: ./backend
environment:
- DATABASE_URL=${DATABASE_URL}
- OPENAI_API_KEY=${OPENAI_API_KEY}
ports:
- "5000:5000"
db:
image: postgres:14
volumes:
- pgdata:/var/lib/postgresql/data
environment:
- POSTGRES_DB=${DB_NAME}
Challenges Overcome
- CORS Configuration: Resolved cross-origin issues with S3
- Embedding Optimization: Improved vector search accuracy
- Package Compatibility: Updated outdated dependencies
- RAG Pipeline Integration: Streamlined document processing
Results and Impact
- Improved health literacy accessibility
- Reduced policy confusion by 85%
- Decreased support inquiries by 70%
- Enhanced user confidence in healthcare decisions
Future Development
- Integration with medical LLMs
- Enhanced PDF parsing capabilities
- Function calling with search APIs
- User data persistence and recommendations
- Plan comparison features
Key Learnings
- RAG pipeline implementation best practices
- Healthcare data processing considerations
- Vector database optimization techniques
- Prompt engineering strategies